Jul. 21, 2017 Research Highlight Physics / Astronomy
Flaws in zinc oxide films add magnetic twist
Why does a non-magnetic material cause electrons to behave like they are interacting with a magnet?
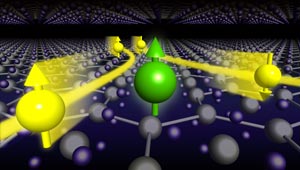 Figure 1: High-mobility electrons (yellow spheres) with different spins are scattered in different directions by a localized magnetic defect (green sphere) at the interface between the oxides MgZnO and ZnO. © 2017 Mari Ishida, RIKEN Center for Emergent Matter Science
Figure 1: High-mobility electrons (yellow spheres) with different spins are scattered in different directions by a localized magnetic defect (green sphere) at the interface between the oxides MgZnO and ZnO. © 2017 Mari Ishida, RIKEN Center for Emergent Matter Science
Scientists often try to eliminate flaws, or defects, from the crystal structures of electronic materials to preserve high conductivity. RIKEN researchers, however, have discovered that some crystal defects can help electrons flow rapidly and with minimal energy loss, generating a quantum state that is highly desirable in the race for low-power electronics1.
Thin films of magnesium–zinc and pure zinc oxides (MgZnO/ZnO) have intrigued Masashi Kawasaki and colleagues from the RIKEN Center for Emergent Matter Science for over 20 years. When stacked, the faces of the two films confine electrons in a thin, nearly two-dimensional region, where they zip along with extraordinary mobility. Continuous improvements in the quality of MgZnO/ZnO crystals mean that electrons in these high-speed interfaces can now travel quite far—some micrometers—before scattering or interacting with other particles.
The team investigated whether MgZnO/ZnO interfaces could act as thermoelectric materials, which generate electricity when heated. This required characterizing the response of interface to both heat and electrical stimulation. The researchers measured the interface’s power dissipation using magnetic fields to deflect electrons from their normal flow—a phenomenon known as the Hall effect. When these experiments were performed at temperatures near absolute zero, a quantum Hall effect emerged, indicating that the system had few defects.
However, the researchers were surprised when they checked power dissipation at temperatures too high for quantum effects to occur. Instead of behaving classically, the current-generated voltages shot up far more than predicted.
“This was very unexpected,” recalls Denis Maryenko. “We expected the Hall effect to show classical linear increases with applied magnetic field. But instead we saw additional, nonlinear enhancements.”
“We used different samples and experimental setups, but the nonlinearity was always there,” says Maryenko. “We talked to many scientists, and everyone agreed we were seeing the anomalous Hall effect, but initially no one could explain it.”
Collaboration with theorists revealed one possible solution to the magnetic puzzle. If a few defects remain at the MgZnO/ZnO interface after thin-film fabrication, these would likely be filled by spin-polarized, single electrons. These defects act as effective magnetic moments that twist flowing electrons from their paths and initiate another Hall effect through a process known as skew scattering (Fig. 1).
“As a way to produce the anomalous Hall effect, one mechanism for producing skew scattering was almost completely forgotten,” says Maryenko. “But if we return to low temperatures, we may see how localized magnetic moments alter the quantum Hall states with impacts for applications such as quantum computing. It proves you have to pay attention to defects—sometimes they can be very useful and bear surprises.”
Related contents
- Super-material holds a quantum surprise
- Defrosting a magnetic mystery
- Electrons moving in a magnetic field exhibit strange quantum behavior
References
- 1. Maryenko, D., Mishchenko, A. S., Bahramy, M. S., Ernst, A., Falson, J., Kozuka, Y., Tsukazaki, A., Nagaosa, N. & Kawasaki, M. Observation of anomalous Hall effect in a non-magnetic two-dimensional electron system. Nature Communications 8, 14777 (2017). doi: 10.1038/ncomms14777