私たちはものの形を立体的に把握し、例えばコップがどんな向きに置かれていても、「これはコップだ」と認識することで周りの環境を理解できます。人間は、このように環境を理解する力を当たり前のように備えていますが、これをロボットに搭載するのは簡単ではありません。川西 康友 チームリーダーは、ロボットがものの形を立体的に把握するための効率的な手法を開発しました。これは、ロボットが初めて見る「未知物体」を学習していくのに役立つ成果です。

一つのロボットを複数のチームで開発
2020年にスタートしたガーディアンロボットプロジェクト(GRP)は、人と長く一緒に暮らせるロボットの実現を目指している。具体的には、ロボットが何をすべきかを自分で考え、実行してくれること、そして、そのロボットに「こころ」があると人が感じられるようにすることが目標だ。その目標に向けて、川西 チームのほか、言語や動作でのやりとりを研究するチームや心理学からアプローチするチームなどが共同してロボットの開発に取り組んでいる。
最初に開発した「ぶつくさ君」は、家の中を模した研究室をパトロールし、自分が見たものや自分がやったことを音声で逐一、"ぶつくさ"と報告するものだった。さらに、知っている人に会えば、「○○さん、こんにちは」と話しかけて用事を聞くし、コップがテーブルの上にあることを覚えていて、「コップは今どこ?」と問われればテーブルに確認しに行く。このロボットの開発で川西 チームリーダーは、人の認識やコップなど室内にあるさまざまな物体の認識を担当した。
GRPでは現在、「Indy(インディ)」というロボットを開発中で、川西 チームもIndyに高度な認識機能を搭載すべく研究を進めている。その一つとして、今回、ロボットが初めて見つけた物体の立体的(3次元的)な形を効率的に学習する手法を開発した。
少数枚の画像から立体的な形を再現
今回開発した手法のもとになっているのは、2020年に登場したNeRF(ナーフ:Neural Radiance Fields)という技術だ。例えば花びんをいろいろな方向から撮影した画像を処理することで、その花びんを任意の視点から見た画像を生成するモデルができる。NeRFでは、ニューラルネットワークを使ってこのモデルを実現する。ニューラルネットワークとはAIの手法の一種で、人間の脳内の神経細胞の働きをまねたやり方でデータを処理するものだ。
すでにメタバース(仮想空間)などに利用されているこの技術をロボットに搭載すれば、ロボットは頭の中で、花びんなら花びんを3次元的に想像できるようになる。「しかし、問題はその学習のために何百枚もの画像を撮影しなければならないことです。私たちは、もっと効率的に学習させる方法が必要だと考えました」。そこで川西 チームリーダーは、金岡 大樹 研修生(九州工業大学 大学院生)らと共に、なるべく少ない枚数の画像で学習する方法の開発に取り組んだ。
NeRFでは、撮影した観測画像を用いて学習する。学習では、対象の物体を観測画像と同じ視点から見たさまを想像させ(生成し)、生成した画像と観測画像との差が小さくなるようにモデルを更新していく。当然ながら、観測画像の枚数が少ないと別視点から見た画像をうまく生成することが難しくなるため、枚数の少なさを補う工夫が必要になる。
川西 チームリーダーらは、観測画像の代わりに、画像の特徴を数値化した「特徴ベクトル」を利用する方法を考え出した(図1)。ManifoldNeRFと名付けたこの手法では、わずか8枚程度の画像で学習でき、別視点においても実際の観測画像と近い画像を得ることができた(図2)。
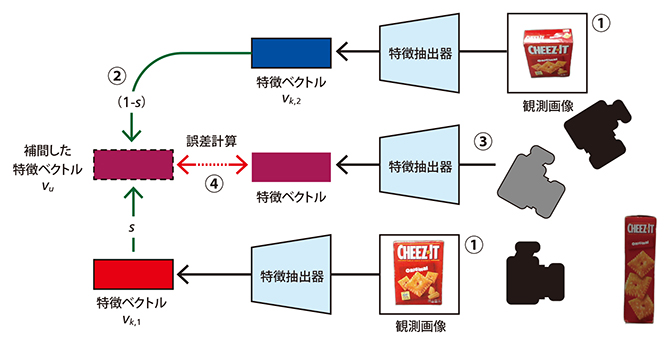
図1 物体を撮影した少数の画像から任意視点の画像を生成する手法:ManifoldNeRF
私たちが2枚の画像を比較するときに色や明るさなどの特徴を手掛かりにするのと同様に、特徴抽出器(AIの一種)も画像からさまざまな特徴を抽出し、それを数値化する。AIが何を特徴として抽出しているかは人間には分からないが、各画像について1,000個程度の特徴の数値が並んだ特徴ベクトルを算出する。川西 チームリーダーらは、物体を見る視点が変化していくときには、特徴ベクトルも連続的に変化すると仮定して、まばらな画像の間にくる画像の特徴ベクトルをつくり出すことにした。まず、①2枚の観測画像の特徴ベクトルをそれぞれ求める(vk,1、vk,2)。次に、②それらを平均することで2枚の中間に当たる視点の画像の特徴ベクトルを求め(vu)、これを正解の特徴ベクトルとする。一方、③NeRFで同じ視点の画像を生成し、その特徴ベクトルを算出する。④その特徴ベクトルが正解の特徴ベクトルに近づくようにモデルを修正する。観測画像のない視点であっても、特徴ベクトル同士を比較することで、生成した画像の良し悪しを判断できるのがミソである。この成果を報告した論文は、英国の視覚情報処理分野の権威ある学会(British Machine Vision Conference 2023)での発表論文の一つに採択された。

図2 8枚の画像を用いた画像生成実験の結果
ManifoldNeRFと、DietNeRF(ManifoldNeRFとは違う方式で少数枚の画像を使って学習する手法)で、同じ8枚の画像を用いて正解画像と同じ視点の画像を生成する実験をした。ManifoldNeRFでは正解画像に近い画像が得られているが、DietNeRFでは欠損や残像のようなアーティファクト(画像の乱れ)が見られた。
映画を見て抱いた夢をここでかなえる
川西 チームリーダーが、ManifoldNeRFにより、ロボットがものの形を効率よく学習できるようにしたいと考えたのは、ロボットの自律的な学習のためだという。「研究室環境ではロボットに事前にあらゆるものの形を学習させることができますが、ロボットがだれかの家に行ったとき、目にするのはすべて未知のものです。私たちは日常生活で新しいものに出会ったとき、向きを変えたり、ひっくり返したりして眺めることで、『これはこういう形なんだ』と覚えますが、ロボットにも同様に、物体をじっと見ただけで、頭の中でその形をちゃんと想像できるようになってほしいのです。そうすれば、次に同じものを見たときに、前に見たものと同じ物体だとすぐに認識できるようになりますからね」
「目指しているのは、ロボットが事前に学習していない未知物体を普段の生活の中で自分で学習し、例えば人との会話の中で、赤くて丸いこの物体は『リンゴ』と呼ぶものなのだと認識できるようになること。自分で学んでどんどん賢くなるロボットをつくりたいのです」と、川西 チームリーダーは静かな口調ながら熱く語る。
川西 チームリーダーは高校生の頃、人と同じ愛の感情を持ち母に愛されることを願うロボットが登場する映画『A.I.』を見て、そういうロボットを開発する夢を抱いたという。その夢を実現すべく、着実に歩を進めている。
(取材・構成:青山 聖子/撮影:大島 拓也/制作協力:サイテック・コミュニケーションズ)
関連リンク
- 2023年9月27日ガーディアンロボットプロジェクトニュース「金岡研修生・薗頭研究員・川西チームリーダーらの論文がBritish Machine Vision Conference(BMVC2023)に採択されました」
- 2021年4月19日クローズアップ科学道「人がこころを感じるロボットを目指して」
この記事の評価を5段階でご回答ください